CLIP-RT: Learning Language-Conditioned Robotic Policies from Natural Language Supervision
RSS 2025
1Seoul National University 2Tommoro Robotics
TL;DR
We explore how non-experts can teach robotic skills only through natural language supervision.
We propose a VLA model that learns visuomotor policies directly from this supervision.
Teaching robots desired skills in real-world environments remains challenging, especially for non-experts. A key bottleneck is that collecting robotic data often requires expertise or specialized hardware, limiting accessibility and scalability. We posit that natural language offers an intuitive and accessible interface for robot learning. To this end, we study two aspects: (1) enabling non-experts to collect robotic data through natural language supervision (e.g., “move the arm to the right”) and (2) training robot policies directly from this supervision. Specifically, we introduce a data collection framework that collects robot demonstrations based on natural language supervision and further augments these demonstrations. We then present CLIP-RT, a new vision-language-action (VLA) model that learns language-conditioned visuomotor policies from this supervision. CLIP-RT adapts the pretrained CLIP model and learns to predict language-based motion primitives via contrastive imitation learning. We train CLIP-RT on the Open X-Embodiment dataset and finetune it on in-domain data collected by our framework. In real-world evaluations, CLIP-RT demonstrates strong capabilities in learning novel manipulation skills, outperforming OpenVLA (7B parameters) by 24% in average success rates, while using 7x fewer parameters (1B). We further assess CLIP-RT’s capabilities in few-shot generalization and collaborative scenarios involving large pretrained models or humans. In simulated environments, CLIP-RT also yields strong performance, achieving a 93.1% average success rate on the LIBERO benchmark with an inference throughput of 163 Hz.
Recent work has made significant progress toward generalist robotic policies using large-scale robot demonstration data. However, collecting these demonstrations often requires expertise and access to specialized hardware (e.g., teleoperation systems). This barrier severely limits accessibility, restricting the number of participants and environments from which data can be gathered. Consequently, this limited accessibility inherently hinders both the scalability (the volume of data) and the diversity (the range of scenarios and behaviors recorded) of the resulting datasets. How can non-experts train robotic policies without relying on specialized expertise or devices for data collection?
We already have an intuitive and accessible interface for robot learning: natural language. In this work, we explore an approach for training robotic skills solely through natural language. It includes:
A framework for robotic data collection based on natural language supervision
VLA model that learns visuomotor skills directly from natural language supervision
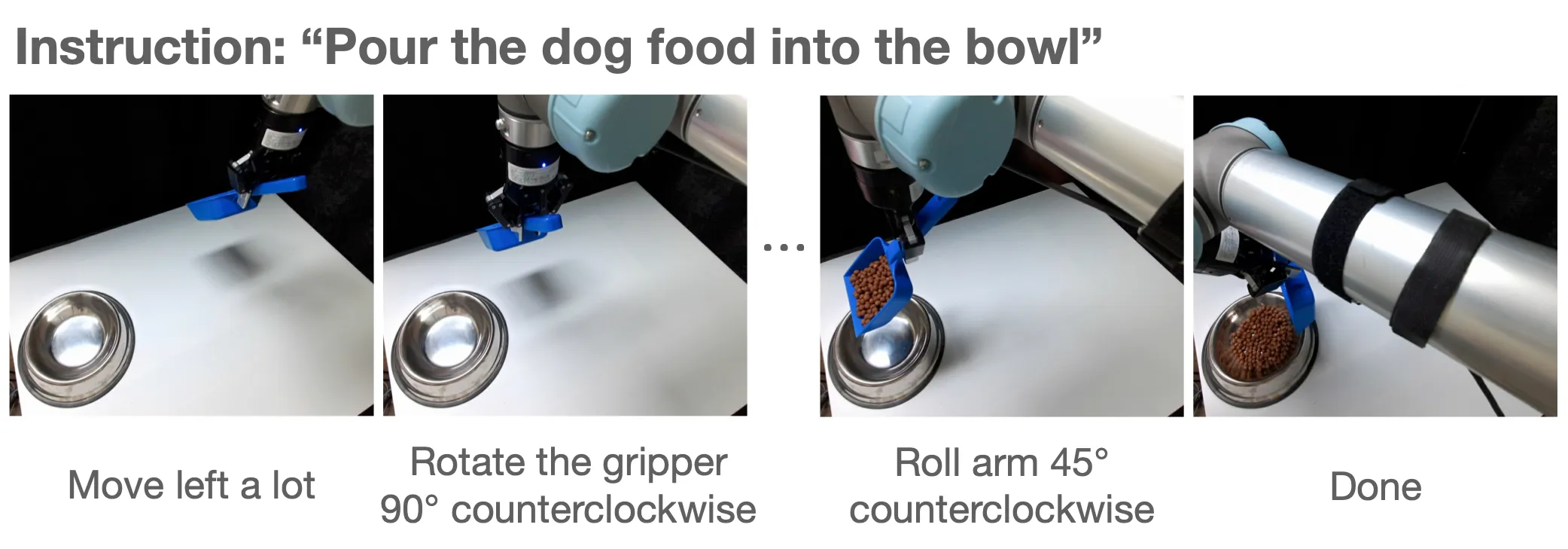
We propose a language-based teleoperation method which leverages the in-context learning capabilities of large language models (LLMs). We collect 10 episodes for each skill through language-based teleoperation
1. Provide initial language instruction (e.g., “Pour the dog food into the bowl”)
2. Provide natural language supervision in each state to complete the instruction
3. LLM translates the language supervision into the end-effector action based on the text prompt
4. Repeat step 2 and step 3 until the episode ends
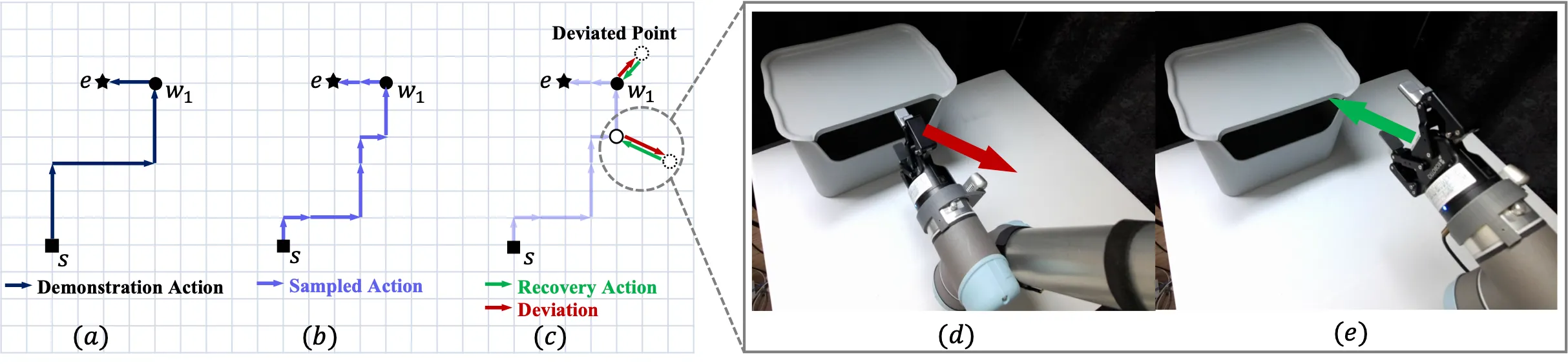
We augment the demonstration data collected by humans based on a method called stochastic trajectory diversification (STD), consisting of two parts:
(1) The Diversification phase diversifies the expert trajectory into multiple alternative trajectories
(2) The Recovery phase intentionally deviates from the original trajectory and then executes a recovery action to return to the original path. Recovery action is utilized in training
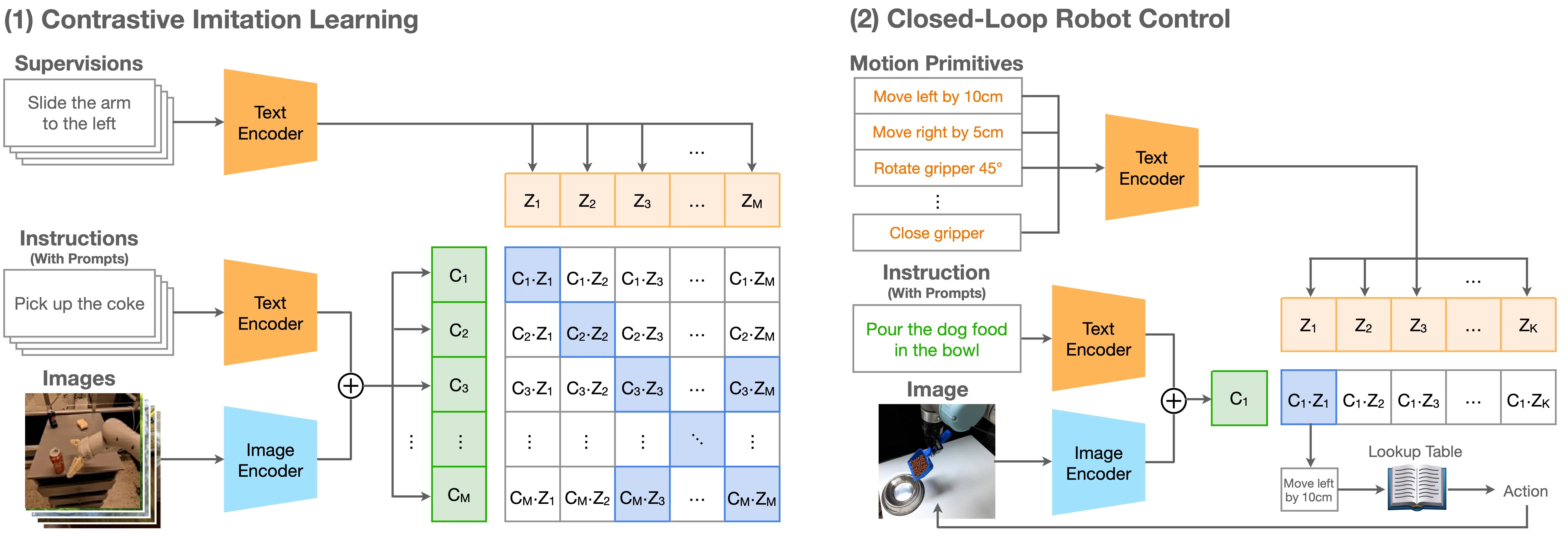
We propose a new VLA model, CLIP-RT which extends the idea of CLIP to robot learning to learn language-conditioned policies from natural language. Different from other VLA models, CLIP-RT learns to predict robotic actions represented in natural language (e.g., “Move arm left”) based on contrastive imitation learning. Furthermore, CLIP-RT is a discriminative VLA model that predicts the language-based motion primitive in the predefined list of motion primitives.
The goal of contrastive imitation learning is to optimize the pairwise similarity between language supervision and contextual information (i.e., the current scene and language instruction). We first train CLIP-RT on Open X-Embodiment (OXE) dataset and then finetune it on our collected in-domain data. Since the OXE dataset does not contain natural language supervision, we transform existing low-level end-effector actions into natural language supervision to train CLIP-RT.
In each time step, CLIP-RT selects the language-based motion primitive with the highest similarity score. The selected motion primitive is translated into the lower-level end-effector commands based on a pre-defined lookup table. Since CLIP-RT is a discriminative model, CLIP-RT can predict action in a single forward pass without autoregressive decoding. This model requires 7GB of GPU memory and runs at 16Hz (one H100 GPU using float32 precision) and 8Hz (one NVIDIA RTX 3090 GPU using float32 precision) without applying any speed-up tricks, such as model quantization and compilation.
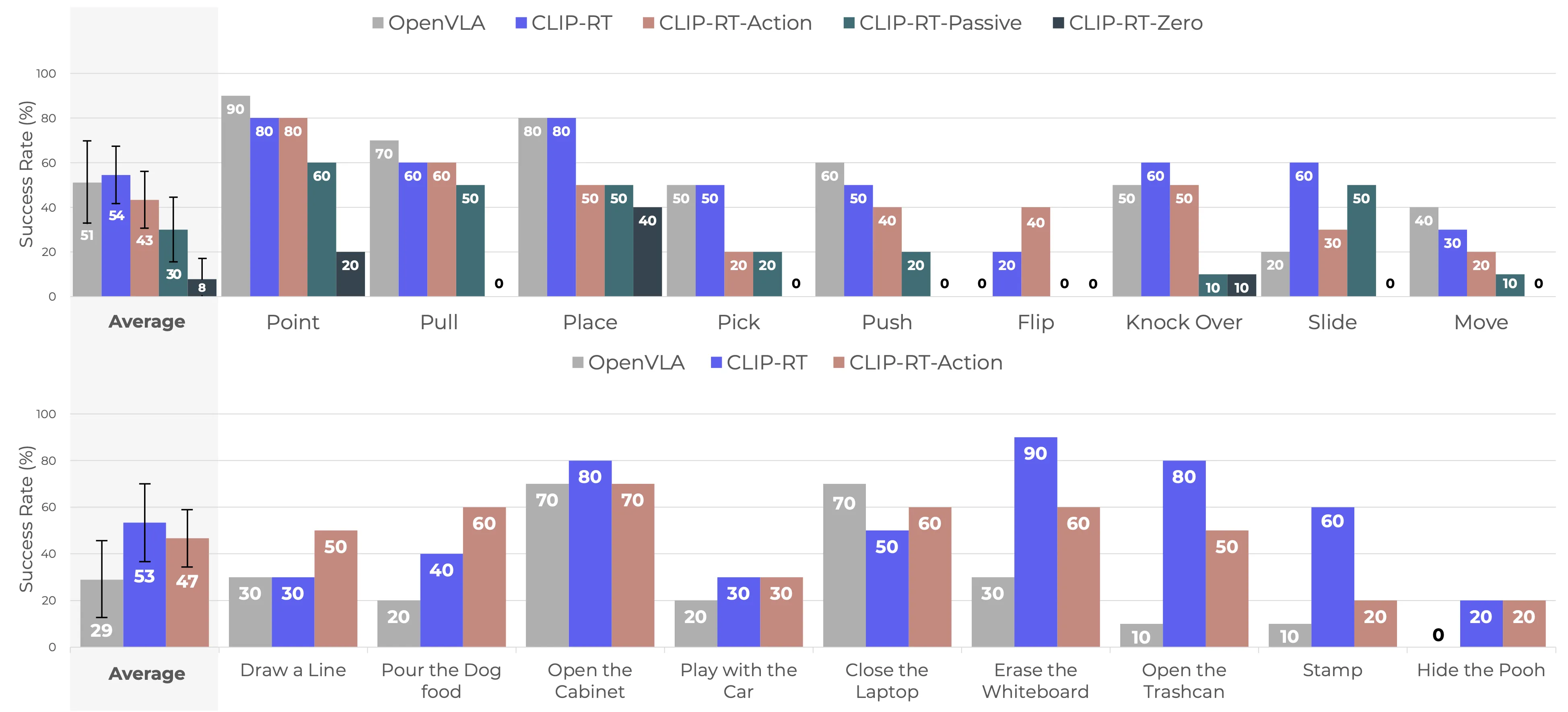
We evaluate CLIP-RT on 9 Common tasks (Top) and 9 Novel tasks (Bottom); Arranged in ascending order based on average steps per episode.
Key Takeaways
1. CLIP-RT outperforms OpenVLA in average success rates by 3% (Common) and 24% (Novel).
2. Natural language supervision significantly increases performance (vs CLIP-RT-Action)
3. STD boosts the overall performance (vs CLIP-RT-Passive)
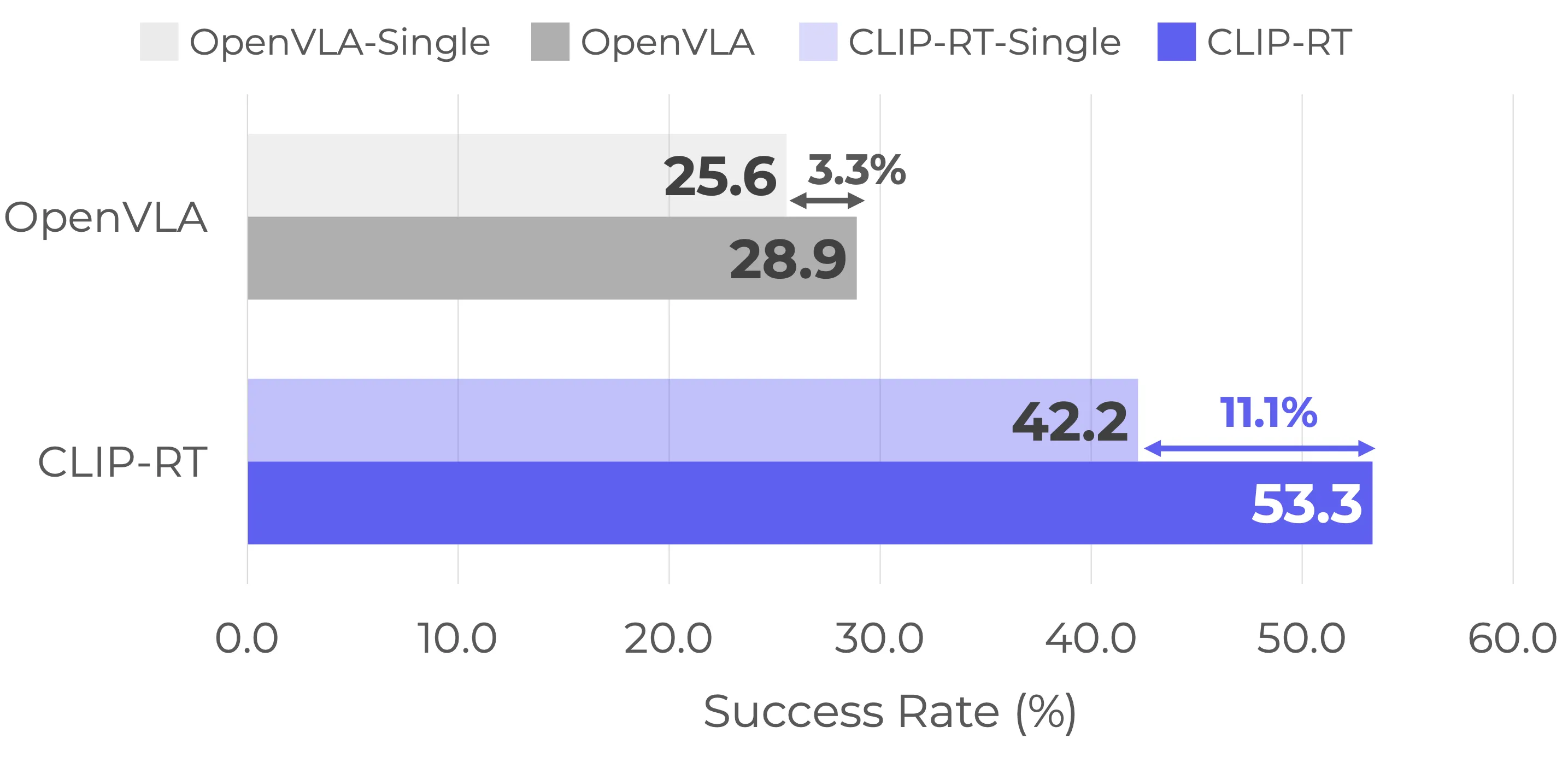
Where does the significant performance gap between CLIP-RT and OpenVLA on Novel tasks come from? One of our hypotheses is that CLIP-RT effectively learns the shared structure across diverse robotic tasks by utilizing language-based motion primitives as basic building blocks. To verify this, we train a single-task policy for each Novel task and evaluate the performance of each model. OpenVLA-Single and CLIP-RT-Single denote the performance of single-task policies for each model. CLIP-RT benefits more on multi-task policies (+11.1%) compared with OpenVLA (+3.3%). It indicates that CLIP-RT benefits more from shared knowledge across diverse robotic tasks. In other words, learning more generalizable and transferable representations is one of the factors that CLIP-RT performs well on Novel tasks.
Another factor is attributed to the use of natural language supervision. As shown in the main results, CLIP-RT consistently outperforms a baseline model, CLIP-RT-Action that learns action tokens from scratch similar to existing VLA models. This observation implies that the use of natural language supervision enhances CLIP-RT’s generalization capabilities. To delve into this more deeply, we visualize how these models embed each motion primitives.
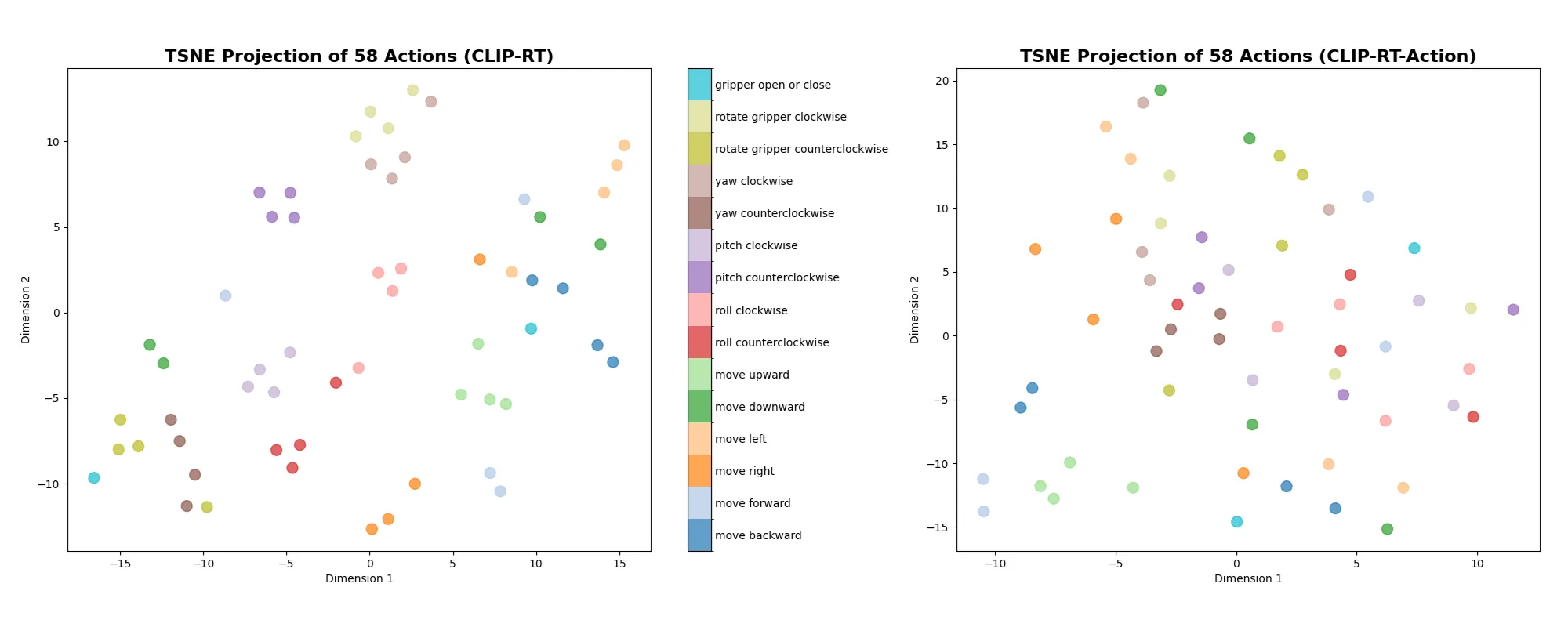
The figure above shows the t-SNE projection of 58 motion primitives for CLIP-RT (left) and CLIP-RT-Action (right). We categorize motion primitives into 16 groups based on the type of displacement. As shown in the Figure, CLIP-RT tends to embed the same groups of motions closer, while CLIP-RT-Action does not show clear structures in its embeddings. It implies that natural language supervision enables CLIP-RT to leverage inherent language priors in the pretrained vision-language model (i.e., CLIP), facilitating the learning of more structured and semantically meaningful action representations. We conjecture that these language priors improve the generalization capabilities of CLIP-RT.
Our paper describes other interesting results, such as (1) collaborating CLIP-RT with humans or large pretrained models and (2) few-shot generalization capabilities.
While our primary focus is on training real-world robots through language-guided data collection, we further evaluate CLIP-RT on the LIBERO simulation benchmark to study the following questions:
Generality: Is CLIP-RT applicable to environments with offline, human-teleoperated demonstrations?
Performance: Does CLIP-RT remain effective in a controlled simulation setting?
To make CLIP-RT compatible with the LIBERO simulation benchmark, we adapt CLIP-RT to predict continuous actions. Please check our paper if you want to check the details of the adaptation.
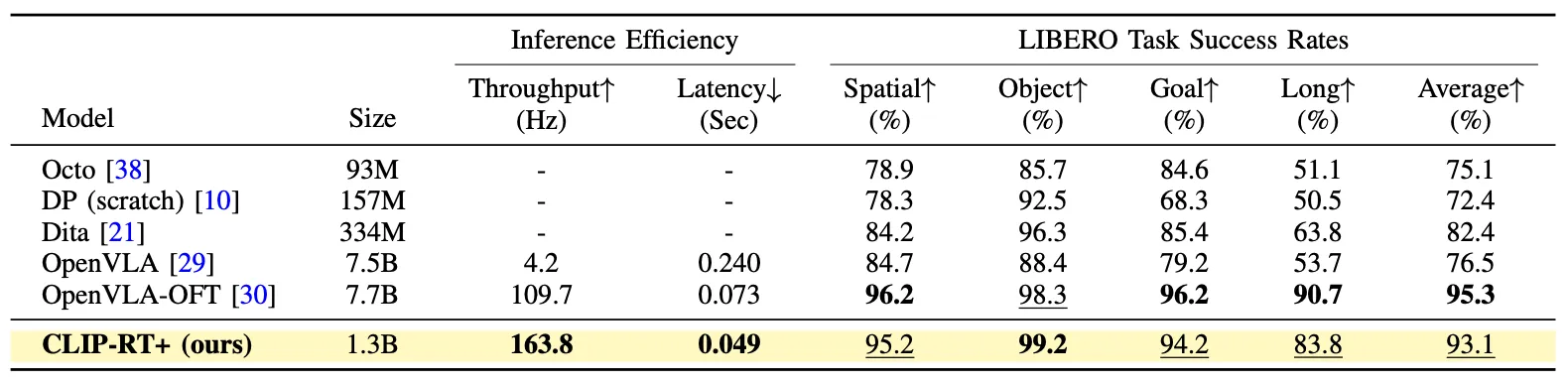
The recent state-of-the-art VLA model, OpenVLA-OFT, achieves the highest average success rate of 95.3%. However, CLIP-RT+ shows comparable performance across all task suites with an average score of 93.1%, while using 6x fewer parameters (1.3B) compared with OpenVLA-OFT (7.7B). Surprisingly, CLIP-RT+ attains a near perfect success rate (99.2%) on the LIBERO-Object task suite, indicating strong generalization to unseen objects in simulation environments.
Furthermore, we measure the throughput and latency on an NVIDIA A100 GPU. CLIP-RT+ achieves 39X improved throughput (4.2Hz to 163.8Hz) compared with OpenVLA based on its lightweight design and the action chunking technique. When compared to OpenVLA-OFT using the same action chunk size of 8, CLIP-RT+ improves both throughput and latency by approximately 49%.
This paper presents CLIP-RT, enabling non-experts to teach robots new manipulation skills through natural language, making robot learning more accessible and scalable for everyday users. We demonstrated the effectiveness of CLIP-RT on both real-world and simulated environments.
@article{kang2024cliprt,
title={CLIP-RT: Learning Language-Conditioned Robotic Policies from Natural Language Supervision},
author={Kang, Gi-Cheon and Kim, Junghyun and Shim, Kyuhwan and Lee, Jun Ki and Zhang, Byoung-Tak},
journal={arXiv preprint arXiv:2411.00508},
year = {2024}
}
This work was partly supported by the IITP (RS-2021-II212068-AIHub/10%, RS-2021-II211343-GSAI/15%, RS-2022-II220951-LBA/15%, RS-2022-II220953-PICA/15%), NRF (RS-2024-00353991-SPARC/15%, RS-2023-00274280-HEI/10%), KEIT (RS-2024-00423940/10%), and Gwangju Metropolitan City (Artificial intelligence industrial convergence cluster development project/10%) grant funded by the Korean government.